
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 패스트캠퍼스 #자료구조 #코딩테스트 #배열
- HEG
- 아셈듀오 후기
- 데이터 시각화 포트폴리오
- 키워드시각화
- 공모전후기
- 미래에셋 공모전
- CRM
- 무신사 데이터분석
- 데이터 포트폴리오
- 아셈듀오
- 테이블계산
- 교환학생주거
- 제네바기숙사
- 데이터공모전
- 리뷰분석
- 제네바경영대학교
- 제네바주거
- 아셈듀오 선정
- 파이썬
- 텍스트분석 시각화
- 교환학생 장학금
- tableau
- 두잇알고리즘코딩테스트
- MairaDB
- 태블로
- 태블로 포트폴리오
- 교환학생
- 데이터 분석 포트폴리오
- 제네바
Archives
- Today
- Total
민듀키티
[논문리뷰] Deep Reinforcement Learning from Human Preferences 본문
Introduction
(1) DRL의 어려움
- 명확하고 정확한 Reward Function을 설계하기 어려워
- 예를 들면 로봇이 clean a table or scramble an egg ⇒ 정량적인 보상 함수를 만들기는 극도로 어려운 상황
- clean a table : ‘깨끗하다’ 라는 기준이 모호하고 보상함수 설계 어려움 (먼지 1개당 1점 ? 접시를 싱크대에 넣으면 5점?) → 주관적인 보상 설계
- scramble an egg : 섬세한 조작 필요 ( 계란을 깨고, 볼에 넣고, 젓고, 팬에 붓고 등 ), 보상함수 설계 어려움 (계란이 익었을 때 10점?)
- 예를 들면 로봇이 clean a table or scramble an egg ⇒ 정량적인 보상 함수를 만들기는 극도로 어려운 상황
(2) 논문의 접근 방식
- 사람이 직접 Reward Function을 만들지 않고, Human Preferences (인간의 선호)를 활용하여 보상 함수를 학습
- STEP 1 : 에이전트가 다양한 방식으로 행동한 짧은 '궤적 세그먼트(trajectory segments)' (예: 짧은 비디오 클립) 두 개를 사람에게 보여줌
- STEP 2 : 사람에게 비교 질문을 던짐
- "클립 A가 더 좋아요”, "클립 B가 더 좋아요”, "둘 다 비슷해요 / 차이를 모르겠어요” 이렇게 답변을 함
- 장점
- 비전문가도 가능 : 복잡한 지식 없이 누구나 쉽게 피드백 할 수 있음
- 경제적인 피드백 : 주 짧은 클립 두 개를 비교하는 것은 시간이 거의 들지 않아
- 복잡한 행동 학습 : 사람이 보상 함수를 만들 수 없었던 새로운 복잡한 행동 (예: 로봇의 백플립)도 학습 가능
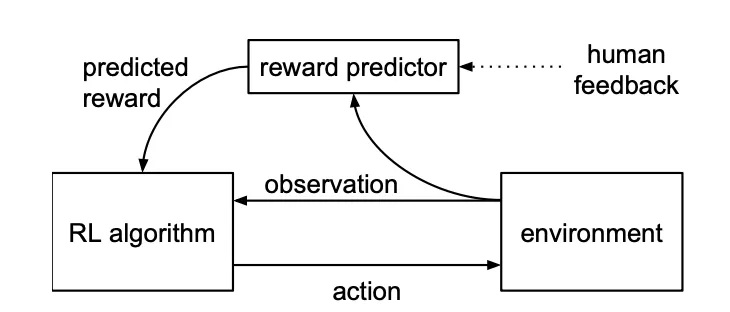
- 모델
- RL algorithm → environment → observation → RL algorithm
- AI 에이전트 (RL algorithm)는 환경(environment)에 '행동(action)'을 하고, 환경으로부터 '관찰(observation)'을 받습니다.
- RL algorithm → human feedback → reward predictor
- 에이전트가 환경에서 행동하면서 생성된 trajectory segments (짧은 행동 비디오 클립)들이 인간에게 전달
- 이 클립들을 보고 인간 피드백(human feedback) (즉, "둘 중 어떤 클립이 더 나은가요?")을 정답 제공
- 이 인간 피드백은 보상 예측기(reward predictor) 모델을 학습
- RL algorithm → environment → observation → RL algorithm
Preliminaries and Method
(1) Setting and Goal
- Agent-Environment Interaction
- Agent : Environment와 상호작용하는 주체
- Environment : 에이전트가 행동하고 관찰을 받는 공간
- 각 시간 t마다 에이전트는 환경으로부터 관찰 Ot∈O를 받고, 환경으로 행동 at∈A를 전송. 여기서 O는 관찰(observation) 공간, A는 행동(action) 공간을 의미 ⇒ 시시각각 변하는 화면(관찰 ot)을 보고, 그것을 바탕으로 어떤 행동(at)지 결정하여 지시
- 기존 강화학습과의 차이점
- 기존 RL : 명확한 수치 보상을 제공하여 에이전트가 이를 최대화하도록 학습
- 이 논문 : 에이전트의 행동이 담긴 두 개의 비디오 클립을 인간에게 보여주고, 인간이 둘 중 어떤 것을 더 선호하는지 판단
- Trajectory Segment
- 에이전트의 경험을 나타내는 단위로, 특정 시간 동안의 관찰과 행동의 순서
- 궤적 세그먼트의 가장 중요한 역할은 인간에게 피드백을 요청하는 '단위'
- σ1≻σ2는 인간이 첫 번째 궤적 세그먼트(σ1)를 두 번째 궤적 세그먼트(σ2)보다 더 선호한다고 판단

(2) Our Method
- Three Asynchronous Processes
- 정책 최적화 (Optimizing the Policy)
- Reward function : 에이전트는 환경과 상호 작용하여 행동(Action) at를 수행하고 관찰(Observation) ot를 받음. 이때, 전통적인 강화 학습처럼 환경에서 직접 보상 rt를 받는 대신, 현재까지 인간 선호도(Human Preferences)를 통해 학습된 보상 함수 추정치 hatr(ot, at)를 사용하여 보상을 계산
- 선호도 추출 (Preference Elicitation)
- 제시된 두 클립 중 어떤 클립을 더 선호하는지를 선택
- 보상 함수 피팅 (Fitting the Reward Function)
- 보상 함수 추정치 hatr 을 인간의 판단을 설명하는 잠재 요인(latent factor)으로 간주
- 정책 최적화 (Optimizing the Policy)
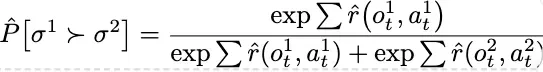
Results
- 이 연구의 핵심 목표는 실제 보상 함수를 알 수 없는 상황에서 인간의 선호도를 통해 RL 에이전트를 훈련시키는 것
(1) Atari
- 인간의 선호도 피드백만으로 복잡한 Atari 게임을 에이전트가 학습할 수 있는지 확인
- 대부분의 게임에서 상당한 성능, 일부 게임에서는 실제 RL의 성능을 능가
- Real Human Feedback vs. Synthetic Feedback
- 대부분의 게임에서 실제 인간 피드백은 동일한 수의 레이블을 가진 합성 피드백보다 약간 낮은 성능을 보임
- 인간 평가의 오류, 여러 계약자 간의 불일치, 또는 레이블이 특정 상태 공간에 과도하게 집중되는 문제
(2) Novel behaviors
- 기존의 잘 정의된 RL 벤치마크 과제에서 벗어나, 보상 함수를 수동으로 설계하기 어려운 실제 문제에 이 방법을 적용할 수 있음을 보여주는 것이 주된 목적
'대학원' 카테고리의 다른 글
| [논문리뷰] Training language models to follow instructions with human feedback (0) | 2025.10.14 |
|---|---|
| [딥러닝 이론] 피드포워드 네트워크 (0) | 2025.09.17 |