
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 제네바경영대학교
- 데이터공모전
- 키워드시각화
- 교환학생주거
- 아셈듀오 선정
- 아셈듀오
- 무신사 데이터분석
- 교환학생
- 제네바
- 아셈듀오 후기
- 리뷰분석
- tableau
- 제네바기숙사
- 두잇알고리즘코딩테스트
- 테이블계산
- 텍스트분석 시각화
- 데이터 분석 포트폴리오
- CRM
- 미래에셋 공모전
- 제네바주거
- 패스트캠퍼스 #자료구조 #코딩테스트 #배열
- 태블로 포트폴리오
- 공모전후기
- 태블로
- HEG
- 교환학생 장학금
- 파이썬
- MairaDB
- 데이터 시각화 포트폴리오
- 데이터 포트폴리오
Archives
- Today
- Total
민듀키티
[딥러닝 이론] 피드포워드 네트워크 본문
1. 인공신경망 (Artificial Neural Network ; ANN)

- 생물학적 뉴런(신경세포)를 모방한 뉴런
- Input을 받고 Weight값에 따라 Output을 도출
- 피드포워드 (Feed-forword) : 정방향으로 가는 것, 다층 퍼셉트론 ( multi-layer perceptron; MLP ),
합성곱 신경망 (convolution network; CNN), 셀프 어텐션 ( self-attention )
- 피드백 (Feed-back) : 디컨볼로션 신경망 (deconvolution network)
- 쌍방향 (bi-directional) : 중첩 오토인코더 (stacked auto-encoders), 깊은 볼츠만 머신 (deep boltzmann machine)
2. 변형함수 (transformation function)의 선책
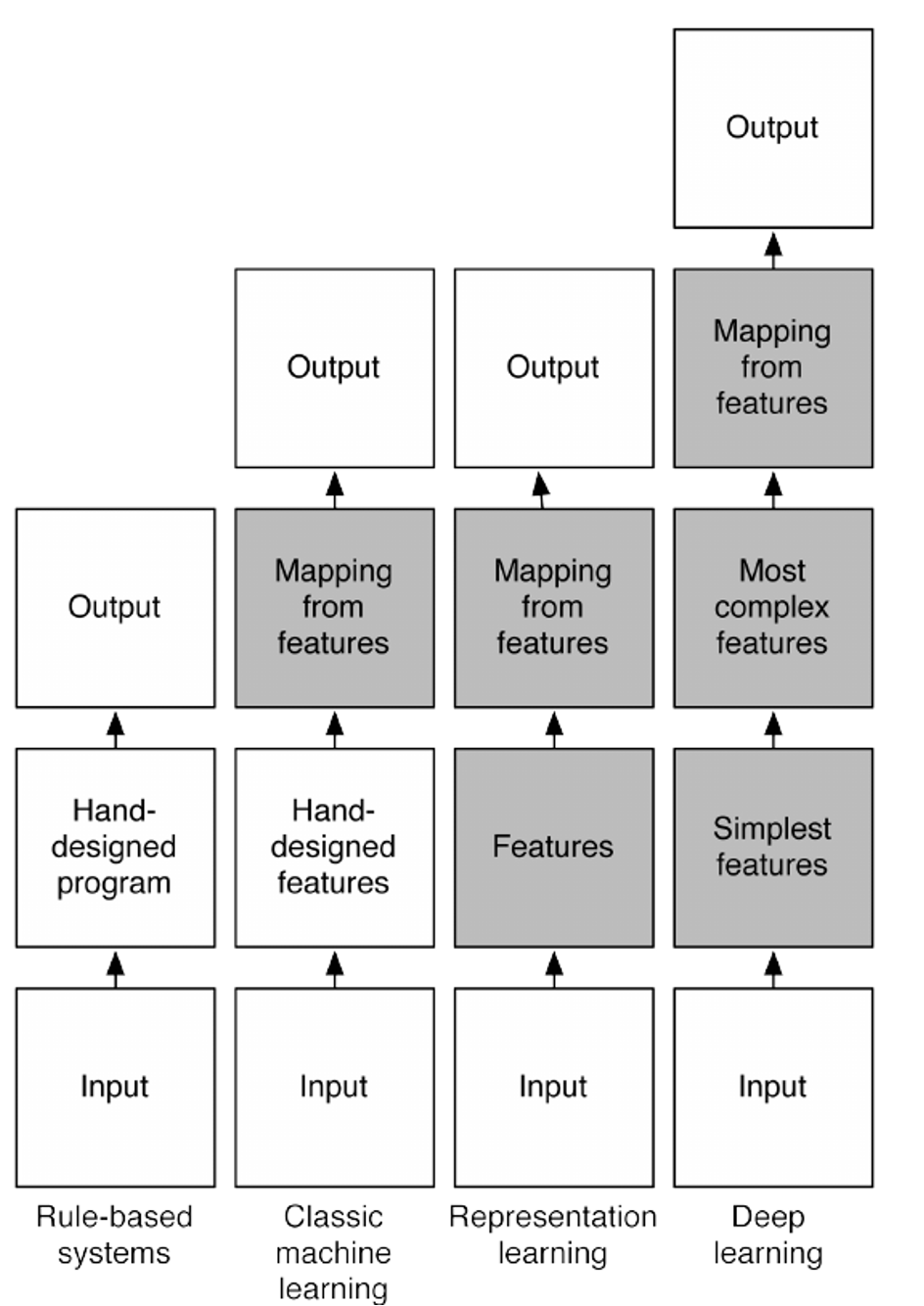
- 딥러닝 이전에는 직접 함수를 디자인함
- 커널 함수를 직접 사용
- 앞단의 Input unit 혹은 전 단계의 hidden units으로부터 선형으로 변형을 받은 뒤, 활성함수 등으로 비선형 변형을 함
- 딥러닝이 변형 함수 자체를 학습하게 함 ( 변형함수는 단, 비선형해야 함 )
- 활성함수를 사용하여 변형을 함

(1) tanh : -1 ~ 1로 압축, 0이 중심 -> Bias shift가 없음, Sigmoid처럼 Saturation 문제(gradient vanishing) -> 중첩될 경우, 1 혹은 -1에 수렴하게 됨, 그래서 변화가 없다고 판단하게 됨
(2) ReLU : 쉽게 미분 계산(gradient)가 된다 (0 혹은 1), Sparsity : 희박하게 활성화 시킬 수 있음, 값이 0인 부분이 많으므로 많은 연산이 줄어듬 (층이 쌓을 수록 좋아져), Sigmoid, Tanh 등 함수는 포화상태가 되기 쉽지만, ReLU는 그렇지 않음 -> gradient vanishing 문제가 발생 안함, Layer가 아주 매우 깊거나, learning rate 등이 잘못 세팅되면 용량을 차지하나 항상 죽어있는 문제가 발생 -> Dying ReLU, 이 역시 gradient vanishing
3. 비용함수 (cost function)와 출력 유닛(output unit)
- ANN을 최적화 하기위한 목적 함수, 즉 비용 함수(cost function)는, 보통 가능도함수를 최대화 (maximum likelihood)를 하는 방법을 선택
- 크로스 엔트로피를 가장 많이 사용

- 출력 유닛의 종류
- 선형 (linear) : 보통 출력 값이 conditional gaussian distribution과 같은 확률 분포이거나 회귀 문제일 때 종종 사용
- 시그모이드(sigmoid) : 이항분류일 때 많이 사용, 0~1사이
- 소프트맥스(softmax) : 다항분류일 때 많이 사용, 0~1사이로 합이 1임, K=2일 때, sigmoid와 같음
정리 )
- 지도 학습적인 접근 : 파라미터를 랜덤으로 초기화, 주어진 라벨로 loss를 최소화하게 학습
- 레이블 샘플이, 실제 데이터와 비교했을 때 비율이 작을 때
- 비지도학습 + 일부분만 지도학습 분류
- 비지도 학습 이후 글로벌하게 지도학습 fine-tune 접근
- Feed-forword step : Input이 모델로 들어가고 Output이 생성, 생성된 결과를 레이블과 비교하여 error을 계산
- Backpropagation step : 체인룰을 이용하여 gradient들을 학습 가능한 파리미터들에게 업데이트
- 각 코스트들은 Forward step과 Backward step을 따로 고민
- Forward step : 학습 뿐만 아니라 서비스 퍼포먼스에도 직결
- Backward step : Online으로 학습을 돌리는 상황이 아니라면, 학습 속도에만 영향
+ 역전파공부 내일
'대학원' 카테고리의 다른 글
| [논문리뷰] Deep Reinforcement Learning from Human Preferences (1) | 2025.10.16 |
|---|---|
| [논문리뷰] Training language models to follow instructions with human feedback (0) | 2025.10.14 |