
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 리뷰분석
- 제네바기숙사
- 공모전후기
- 태블로 포트폴리오
- 미래에셋 공모전
- 데이터 분석 포트폴리오
- 키워드시각화
- 교환학생 장학금
- 무신사 데이터분석
- 제네바
- 데이터공모전
- 테이블계산
- 제네바경영대학교
- 제네바주거
- 패스트캠퍼스 #자료구조 #코딩테스트 #배열
- 데이터 포트폴리오
- 두잇알고리즘코딩테스트
- 아셈듀오
- HEG
- 교환학생주거
- 태블로
- 데이터 시각화 포트폴리오
- 아셈듀오 선정
- CRM
- 파이썬
- 아셈듀오 후기
- 교환학생
- 텍스트분석 시각화
- tableau
- MairaDB
Archives
- Today
- Total
민듀키티
[논문리뷰] Training language models to follow instructions with human feedback 본문
대학원
[논문리뷰] Training language models to follow instructions with human feedback
민듀키티 2025. 10. 14. 22:57Abstract
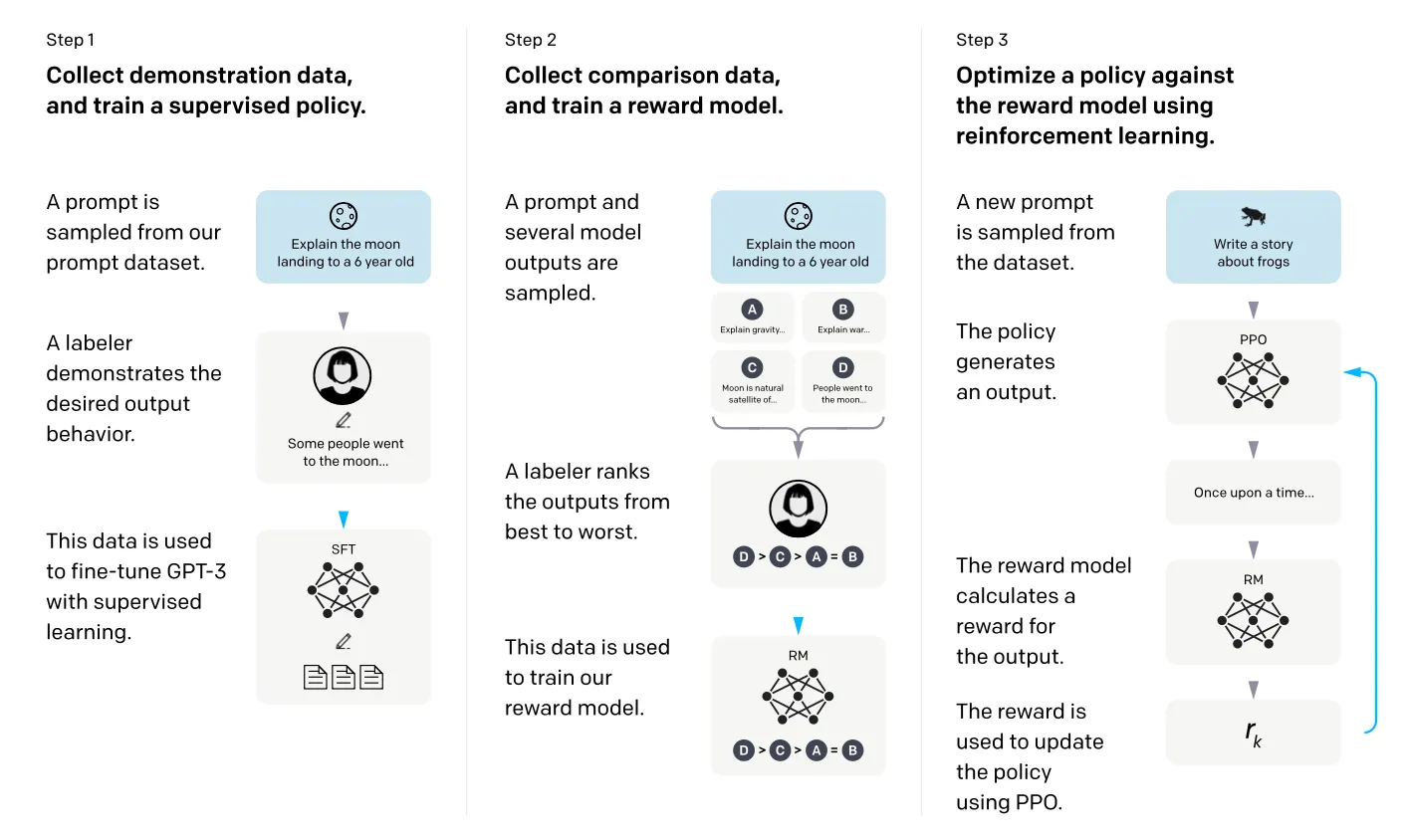
- Instruct GPT : 좋은 응답을 보여주고 → human feedback을 활용하여 → 미세조정 (fine-tuning) 함으로써 3단계 학습 과정을 거침
- 훨씬 더 모델의 크기가 작음에도 불구하고 GPT-3보다 훨씬 더 사용자의 지시를 잘 따름 ( 즉, 모델 크기보다 인간 피드백을 통한 정렬이 더 중요함 )
Introduction
(1) LLM의 문제점
- Untruthful (비진실성), Toxic (유해성), Not helpful (무익함)
- 이를 Misaligned 문제점이라 말함
- LLM은 인터넷 데이터를 기반으로 다음 토큰을 예측하도록 학습되어 있기 때문에, 사용자의 지시를 유용하고 안전하게 따르려는 실제 목표와 정렬되지 않아 원치 않은 행동을 보임
- 그래서 해결책 → human feedback + fine tuning
(2) Fine-tunning with Human Feedback
- 사용자의 명시적 지시(explicit intentions) (예: 특정 작업을 수행하는 방법)와 암묵적 의도(implicit intentions) 를 모두를 따르도록 언어 모델을 훈련하는 것이 목표
- 학습 방법론
- Supervised Fine-tuning, SFT : 레이블러가 원하는 모델 응답 데모를 만듬, 데모 데이터를 사용하여 GPT_3를 지도 학습 방식으로 미세 조정
- Reward Model : 모델의 여러 출력 중 인간 레이블러가 어떤 것을 선호하는지에 대한 비교 데이터셋 수집 , 인간의 선호도를 예측하는 보상 모델을 훈련
- Reinforcement Learning : 훈련된 보상 모델을 보상 함수로 사용, Proximal Policy Optimization Algorithms (PPO) 알고리즘으로 지도 학습 모델을 추가로 미세 조정
- 3가지의 단계를 비유를 하자면
- Supervised Fine-tuning : 모범 답안을 보여주고 따라 하게 만들기
- Reward Model : "어떤 답안이 좋은 답안인가?"에 대한 정확한 채점 기준표를 만듬, GPT-3가 스스로 더 나은 답안을 만들어낼 때 사용될 '피드백' 역할
- Reinforcement Learning : 채점표에 맞춰 스스로 공부하며 실력 향상시키기
- InstructGPT의 성과
- Human Preference : 파리미터 수 InstructGPT 1.3B <<< GPT-3 175B
- Improved Truthfulness: TruthfulQA InstructGPT 가 2배 이상 진실
- Hallucination 감소 : 모델이 원문에 없는 내용을 마치 사실인 것처럼 지어내는 '환각' 현상이 종종 발생하는데 GPT-3의 Hallucination 비율 41%를 21% 절반 가까이 줄였음
- Reduction in Toxicity : Instruct GPT가 독성 있는 출력을 25% 적게 더 생성
- Alignment Tax : LLM을 인간의 의도에 '정렬(align)'시키려고 학습시키다 보면, 때때로 SQuAD (독해 능력)나 DROP (추론 능력) 같은 기존의 공개 NLP 데이터셋에서는 오히려 성능이 떨어지는 현상이 발생
- Generalization Capabilities : 학습할 때 거의 보지 못했던 새로운 종류의 지시(예: 다른 언어나 코딩 관련 질문)도 꽤 잘 이해하고 따름
Methods and experimental details
(1) Dataset
- OpenAI API Playground 사용자 Prompt : OpenAI가 제공하는 "Playground"라는 웹 기반 인터페이스를 통해, 초기 버전의 InstructGPT 모델(이전 버전의 지도 학습 모델)에 사용자들이 직접 입력한 Prompt들이 가장 주된 데이터 소스
- SFT (Supervised Fine-Tuning) 데이터셋 : 미세 조정(fine-tune)하는 데 사용, 레이블러들이 작성한 'Prompt + 원하는 응답(데모)' 쌍으로 이루어진 데이터
- RM 데이터셋 : Prompt에 대해 모델이 생성한 여러 응답(K=4~9개)을 레이블러들이 직접 '선호도 순위'로 매긴 데이터
- PPO (Proximal Policy Optimization) 데이터셋 : 단순히 Prompt들로만 이루어짐, 답은 보상 모델에 의해 평가되고, 그 평가 결과(보상)가 다시 언어 모델을 개선하는 데 사용
(2) Tasks
- Train Data
- labeler가 직접 작성한 프롬포트
- 초기 Instruct GPT 모델에 제출된 API 프롬포트
(3) Models
- 기반 모델
- GPT-3 → 앞에서 언급한 Untruthful (비진실성), Toxic (유해성), Not helpful (무익함) 문제를 해결해야함
- SFP
- "바람직한" 응답의 예시를 보여주면서 모델을 다시 훈련
- 훈련학습 상세
- 16 epochs
- Cosine Learning Rate Decay을 적용 → 학습률 스케줄링 기법 중 하나로, 학습률이 코사인 함수의 형태에 따라 감소하는 방식
- RM
- 인간에게 얼마나 선호될지(바람직한지) 예측하는 보상 모델을 훈련 → 스칼라 값(점수)로 선호도를 나타냄
- 1단계 : 모델 응답 후보 생성 ( K개 - 논문에서는 K를 4개~9개 사이로 설정)
- 재미있는 짧은 스토리 하나 써줘에 대해 K=4개의 응답 A,B,C,D가 생성됨
- 2단계 : 인간 레이블러의 랭킹 작업
- 생성된 K개의 응답을 인간 레이블러(평가자)에게 제시
- 가장 선호하는 응답부터 가장 덜 선호하는 응답까지 순위를 매깁니다.
- 3단계 : 랭킹 데이터를 kC2 비교 쌍으로 변환
- 4단계 : 보상 모델 학습
- 수많은 비교 쌍 데이터(예: "응답 C가 응답 A보다 더 선호된다")를 사용하여 RM을 훈련
- 프롬프트 xxxx와 응답 yyyy가 주어졌을 때, 해당 응답의 선호도를 나타내는 스칼라 값을 출력하도록 학습
- 1단계 : 모델 응답 후보 생성 ( K개 - 논문에서는 K를 4개~9개 사이로 설정)
- 인간에게 얼마나 선호될지(바람직한지) 예측하는 보상 모델을 훈련 → 스칼라 값(점수)로 선호도를 나타냄
- Reinforcement learning (RL)
- 언어 모델 자체가 사용자의 지시를 더 잘 따르도록 스스로 학습하고 발전하게 만드는 과정
- PPO 활용
- 1단계 : SFT 모델을 강화 학습의 시작점인 '초기 정책'으로 사용
- 2단계 : 프롬프트에 대해 응답을 생성 → RM 에 입력하여 스칼라 점수를 받음
- 3단계 : PPO(Proximal Policy Optimization) 알고리즘을 사용하여 모델 업데이트
- 4단계 : PPO-ptx 추가
- RL 학습으로 인해 발생할 수 있는 Alignment Tax (일부 기존 언어 능력 저하)을 완화하기 위함
- 사전 학습 데이터의 로그 가능도(log likelihood)를 증가시키는 그래디언트를 혼합 (모델이 새로운 지시를 따르면서도 이전의 광범위한 언어 지식도 잊지 않도록 함께 학습)
Evaluation & Results
- Alignment : Helpful(도움이 되는), Honest(정직한), Harmless(무해한) 세 가지 기준을 사용하여 모델 평가
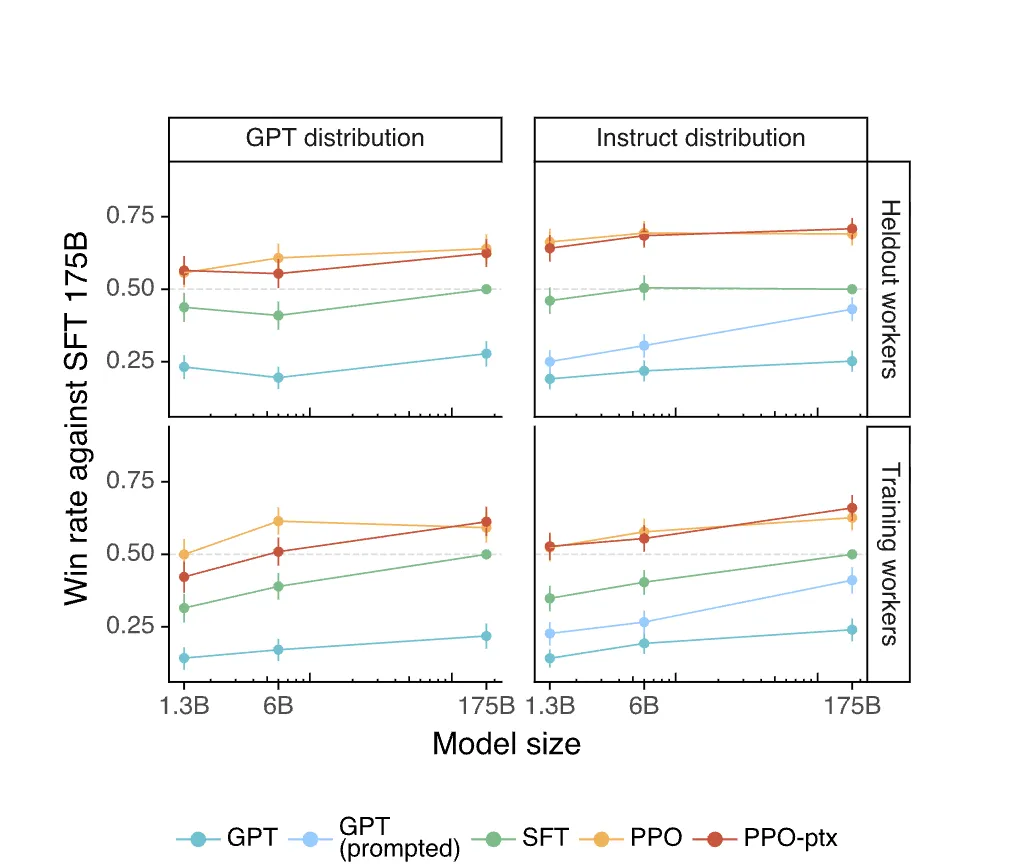
- Results on the API distribution
- 주요 지표 → Human Preference Ratings
- held-out prompt(평가를 위해 따로 남겨둔)
- Human Preference Ratings
- 주요 지표 → Human Preference Ratings
- Evaluations on public NLP datasets.
- 모델이 거짓 정보를 생성하는지(TruthfulQA), 독성 있는 내용을 생성하는지(RealToxicityPrompts), 또는 특정 집단에 대한 편향된 내용을 생성하는지(CrowS-Pairs) 등을 평가
- zero-shot 성능 평가
- "InstructGPT 모델이 Alignment Tax를 겪었는가
- Alignment Tax : 모델을 '착하게' 만들기 위한 훈련(RLHF) 때문에, 모델이 기존에 가지고 있던 특정 NLP 작업(예: SQuAD에서의 질문 응답 정확도) 수행 능력이 오히려 나빠지는 현상
- Results
- 훈련과정에서 Alignment Tax현상을 크게 줄임
- 일부 새로운 지시에도 잘 일반화
- 사람들은 InstructGPT를 압도적으로 선호
- 일반 GPT-3 (프롬프트 추가) → SFT(지도 학습) → PPO(강화 학습) → PPO-ptx(강화 학습 + 사전 학습 데이터 혼합) 순으로 인간 선호도가 지속적으로 향상
'대학원' 카테고리의 다른 글
| [논문리뷰] Deep Reinforcement Learning from Human Preferences (1) | 2025.10.16 |
|---|---|
| [딥러닝 이론] 피드포워드 네트워크 (0) | 2025.09.17 |