Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 교환학생 장학금
- HEG
- 제네바경영대학교
- 데이터 분석 포트폴리오
- 테이블계산
- 제네바주거
- 태블로 포트폴리오
- 교환학생주거
- 데이터공모전
- 교환학생
- 데이터 포트폴리오
- MairaDB
- 무신사 데이터분석
- 키워드시각화
- 텍스트분석 시각화
- 태블로
- CRM
- 공모전후기
- 아셈듀오
- 제네바기숙사
- 패스트캠퍼스 #자료구조 #코딩테스트 #배열
- 제네바
- 데이터 시각화 포트폴리오
- tableau
- 아셈듀오 후기
- 미래에셋 공모전
- 리뷰분석
- 두잇알고리즘코딩테스트
- 아셈듀오 선정
- 파이썬
Archives
- Today
- Total
민듀키티
[논문리뷰] A Survey of Transformers 본문
1. History
- RNN기반의 Sequence-to-sequence
- 인코더-디코더 기반의 기계 번역 (시퀀트 투 시퀀스) 는 입력 문장이 길어짐에 따라 퍼포먼스가 떨어짐 (=long - term dependency)
- LSTM, GRU 등도 완전히 long - term dependency 해결 불가
- Attentional RNN
- Attention구조는 RNN의 long-term dependency 문제를 어느정도 해
- Self-attention
- key, value, query을 모두 같은 소스에 계산하는 경우 (저번에 배운거 !)
2. BACKGROUND

- Complexcity의 개선 -> 성능 개선 -> 도메인 확장
- 후속연구로 많은 종류의 트렌스포머가 많이 나와 (아래와 같이 나눌 수 있음)
- Module level
- Architecture level
- Pre-Train
- Application
- Transformer는 RNN과 비교했을 때, 효율적으로 병렬 계산이 가능
3. Variations of Transformers
- Complexity (복잡성) : O(n^2∗d) 의 속도는 나쁘지 않지만, 전체 transformer의 연산 중 bottle-neck
- Structural prior (구조적인 prior) : Self-attention은 CNN, RNN과 다르게 input에 대한 가정이 없다.
- 해결방법
-
Sparse attention: sparsity bias을 attention mechanism 에 더해 연산을 줄인다.
-
Linearized attention: attention matrix 연산을 kernel feature map로 분리(disentangle)한다. 그 이후, 선형 복잡성을 이루기 위해 역순으로 attention을 계산한다.
-
Query prototype & memory compression: attention의 key, query, value memory pair의 수를 줄여 attention matrix 연산을 줄인다.
-
Low-rank self-attention: low-rank (낮은 계수)로 self-attention 을 정의하여 연산을 줄인다.
-
Attention with prior: CNN/RNN 모델을 추가하여 prior knowledge을 보완하거나, 기능적으로
prior을 추가할 수 있도록 개선한다. -
Improved multi-head mechanism: multi-head attention 로직 자체를 개선한다.
-
Attention 은 기본적으로 모든 query 에 attend을 시도한다.
-
(1) Spare attention
- 실제로 Attention이 필요한 부분은 일부에 불과 -> 제한된 영역에서만 sparer하게 집중
- 아래 식에서 무한대 : 죽임


- Position 기반 sparse attention: 미리 정의된 패턴으로 sparsity을 정의한다.
(2) Attention: sparse attention
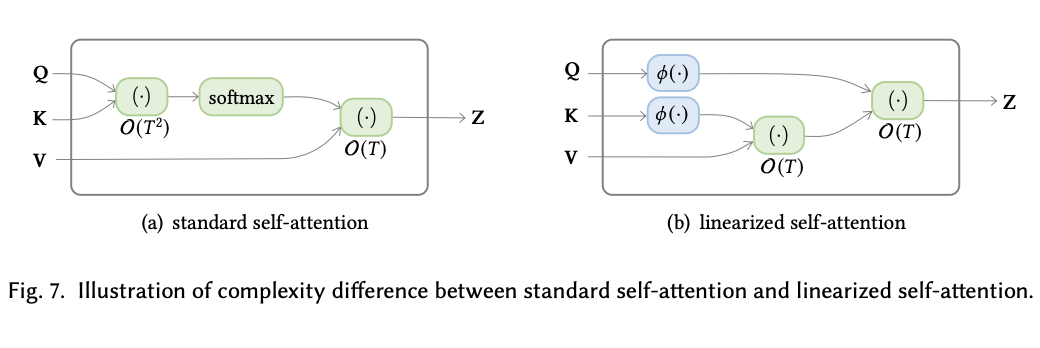
(3) Linearized attention : Kernel method 등을 이용하여 bottleneck인 matrix연산 및 softmax를 linear연산으로 줄임
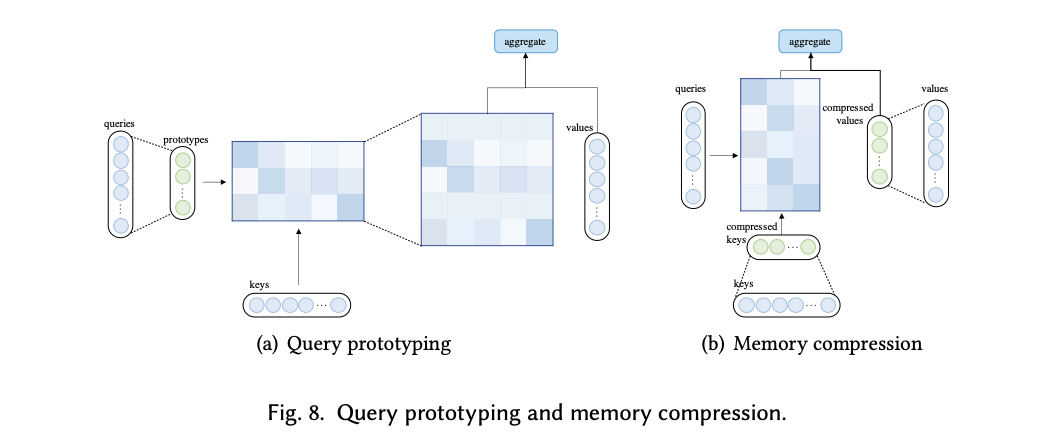
(4) Query prototype & memory compression
- query(디코더의 집중하고자 하는 부분; query prototype)나 key-value (인코더 부분; memory compression) pair의 크기를 줄여