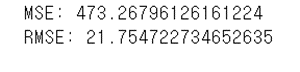파이썬을 활용한 이커머스 데이터분석 (고객별 연간 지출액 예측 - Linear Regression)
1. Train Test Split

Train, Test를 Split 하지 않으면, 새로운 데이터 셋이 들어왔을 때, 잘 맞지 않은 경우가 발생한다.
그림의 경우를 예시로 들자면
오른쪽 그래프는 매우 잘 맞지만, 새로운 데이터가 들어온 왼쪽 그래프는 잘 맞지 않음
-> 그렇기 때문에 Train, Test Split 작업이 필요함
파이썬 코드로는 어떻게 구현 ?
from sklearn.model_selection import train_test_split
X = data.drop('Yearly Amount Spent', axis=1)
y = data['Yearly Amount Spent']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=100)test_size = 0.3 -> test size의 비율을 전체 데이터 셋에서 0.3의 비율로 하겠다
random_state = 100 -> train, test 데이터를 랜덤으로 나누게 되는데, 누가 코드를 실행을 하든 같은 결과를 도출하기 위해서 random_state를 파라미터로 설정을 해준다.
2. 실습에 사용할 데이터 셋 확인하기
(1) 모듈 및 데이터 로딩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('ecommerce.csv')
(2) 상위부분 출력
data.head()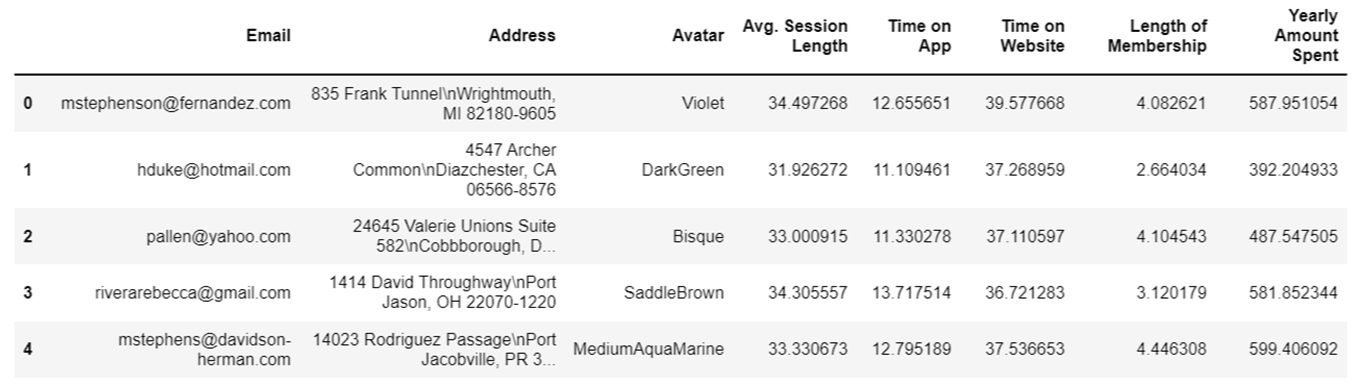
(3) 정보 확인하기
data.info()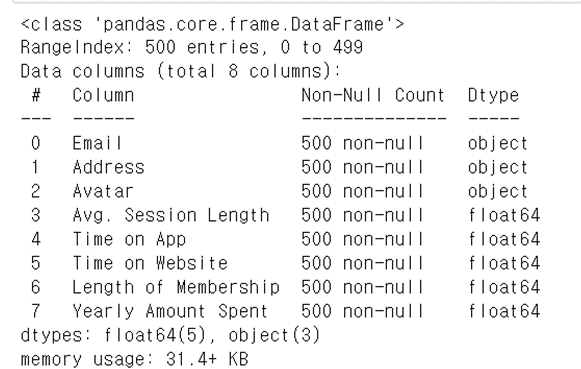
(4) 요약통계량 확인하기
data.describe()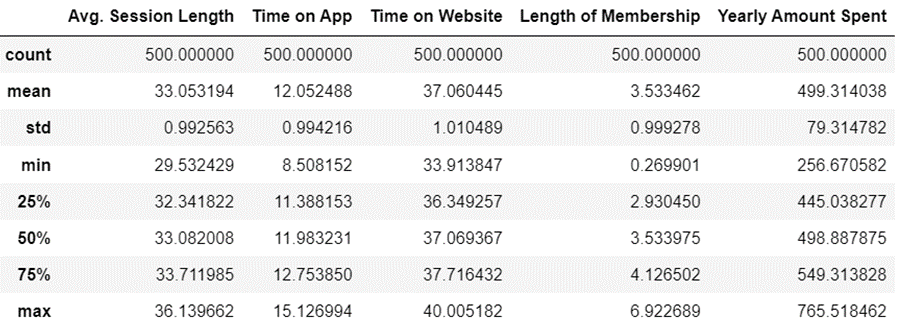
(5) 관계 그래프
sns.pairplot(data)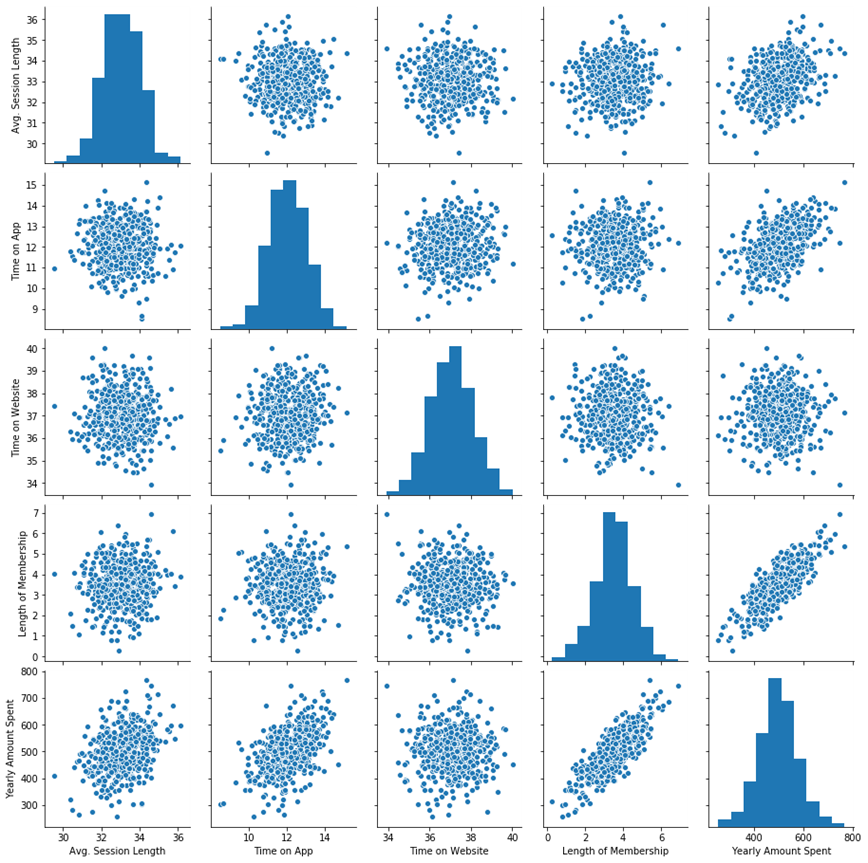
3. 모델을 활용하여 예측하고 평가하기
(1) MSE : 실제값과 예측값의 차이를 제곱해 평균화
(2) 코드 확인
* Linear Regression을 구현하는 데는 많은 방법이 있지만,
Regression Result 결과 정리에 특화된 OLS를 이용하여 구현함
import statsmodels.api as sm
lm = sm.OLS(y_train, X_train).fit()
lm.summary()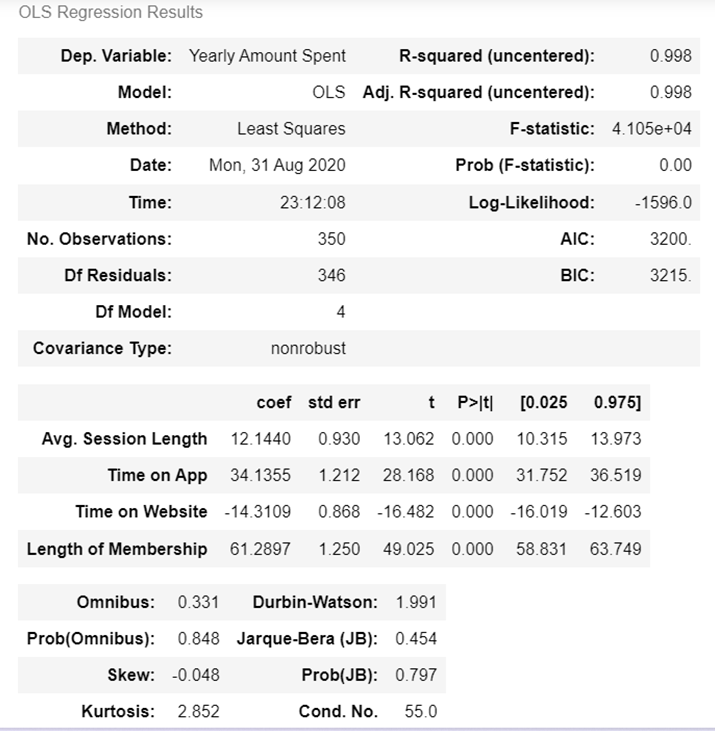
R - Squared : 변수가 많으면, R - Squared 값이 높아짐, 클수록 좋은 모델이다
Adj - R - Squared : 변수가 많으면, R - Squared 값이 높아진다는 단점을 극복하기 위해서 만들어진 것
Coef : 변수의 영향력 정도 (단, 데이터 스케일이 다른데 coef를 비교하는 것은 옳지 않음)
p - value : 신뢰할 수 있는 결과인가? 에 대한 척도 (0.05 이하이면 양호함)
R- Squared ?
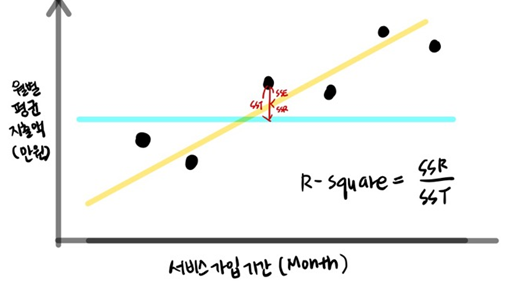
R - Squared는 크면 클수록 좋은 것으로, 일반적으로 0.8 이상이면 좋은 수치라고 이야기 할 수 있다
4. 수식 만들어보기
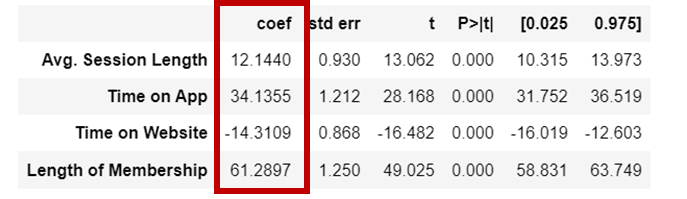
coef를 이용해서 수식을 만들어볼 수 있음 -> 이 수식을 이용하여 예측을 한다.
Y = 12.144 * Avg.Sessoin Length + 34.1335 * Time on App + -14.3109 * Time on Website + 61.2897 * Length of MeberShip
5. 예측 및 평가
predictions = lm.predict(X_test)
predictions
sns.scatterplot(y_test,predictions)
from sklearn import metrics
print('MSE:', metrics.mean_squared_error(y_test, predictions))
print('RMSE:', np.sqrt(metrics.mean_squared_error(y_test, predictions)))